Bioinformatics involves the integration of computers, software tools and databases to address biological issues. Bioinformatics are often used for large experiments that generate large data sets and important large-scale applications that use bioinformatics: genomics, Proteomics.
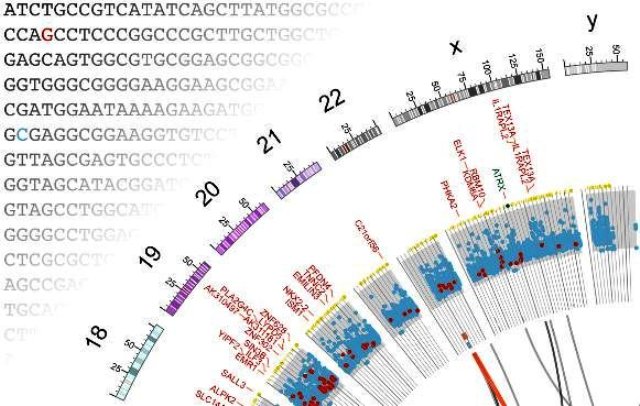
The science of genomic studies expresses genome analysis. The genome can be imagined as a complete set of DNA-deficient DNA sequences that encode the inherited material passed down from one generation to the next. DNA sequences include all genes - the gene is the functional and physical unit of genetics passed from parents to offspring - copies - RNA copies - the first step in translating the genetic code contained within the genome.
The science of genomic studies refers to the extraction and sequencing of all these entities, including genes and RNA copies within an organism. The science of genetic proteins on the other side refers to the analysis of the whole group of proteins or proteomes - a whole set of proteins expressed by a genome or a cell Or tissue or organism at a given time.
In addition to genetic studies and genetics, there are many biological fields that use bioinformatics - metabolic studies and genetic transcription - each of these critical areas of bioinformatics aims to understand complex biological systems.
Many scientists today refer to the next wave of bioinformatics as "systems biology," a way to address new and complex biological issues. These systems biology include the integration of genetic and bioremediation information and bioremediation information to create a complete, structured vision of the biological entity.

The Department of Biological Understanding, in which systems biology seeks to understand all aspects of the organism and its environment by combining different scientific fields.
For example, the path the signal takes in the cell. The way it works in the biology of systems can be addressed. The way in which the common genes interact in this signaling path can be formulated and how the modifications of the results are modified using system biology. Any system in which information is presented in digital form presents a potential application of bioinformatics, so biophysics can be used from single cells to entire ecosystems.
By understanding the complete "parts lists" in the genome, scientists will gain a better understanding of complex biological systems. Understanding the interactions between all these parts in the genome or proteome represents the next level of complexity in the system. Thus, bioinformatics has the ability to present basic ideas within Our understanding and determination of certain diseases or health conditions appear in humans.
The early biometrics of Margaret Dreyhoff in 1968 and her series of protein sequences, known as the genome sequence and structure of the genome, were one of the first important experiments in bioinformatics to apply the program of similarity in sequences to determine the origins of a viral gene .
In this study, scientists used one of the first programs to look for similarities in sequence (FASTP) to recognize that the contents of v-sis - a cancer-causing sequence of the virus - were more closely related to the cellular DNA (PDGF). This amazing finding has provided important mechanical ideas for biologists working to discover how this viral sequence of cancer leads. From this first primary computer application to biology, the field of bioinformatics has expanded.
The growth of bioinformatics is parallel to the development of DNA-deficient DNA sequencing technology. In the same context, the microscope did not evolve in the late 1600's from biological science. Anton van Leeuwenhoek allowed us to consider (DNA) revolutionized bioinformatics, and the rapid growth of bioinformatics can be illustrated by the evolution of DNA sequences in the generic nucleotide repository (GenBank).

Use of computers to process biological information
The wealth of information that characterizes the genome sequence requires the design of software and the use of computers to process this information. Genome sequencing projects have become the main station for many bioinformatics experiments. The Human Genome Sequencing Project is a successful example of genomic sequencing projects, as well as many other genome projects that have been implemented or are under way.
In fact, the first genomes that were extracted were: the genome of viruses (ie, the phage MS2) and the bacteria, and the first independent organism to be sequenced and stored in the general sequence data banks, the H5 (RD-Haemophilus influenzae Rd). This achievement did not make a fuss like the achievement of the human genome, but it is clear that the sequencing of other genomes is an important step for today's bioinformatics, yet the sequence of the genome itself has limited information.
The most important standard for these analyzes is the sequence databases available to the public. Without sequencing databases such as GenBank in which biologists store the sequence information they want, most of the rich information derived from Project genome sequences are available.
In the same way, developments in the microscope have led to discoveries in cell biology. These new discoveries in information technology and molecular biology have led to discoveries in bioinformatics. In fact, an important part of bioinformatics lies in the development of new technology that enables bioinformatics very fast.
In this regard, on the computer science side, the software improvements, the new algorithms and the evolution of computer module technology have enabled biotechnologies to make significant leaps in terms of the amount of data that can be analyzed efficiently. In the laboratory field, the evolution of SAGE, microchip technology, and mass spectrometry of mass spectrometry has helped scientists produce data for analysis at an astounding rate.
Bioinformatics provides both tablet technologies that help scientists deal with large amounts of data from genomic studies, genetics and the way they are interpreted. It also provides bioinformatics and various tools to apply scientific approaches to large-scale data, and should be viewed as a scientific approach to the introduction of many new types of biological questions and different.

Possible types of bioinformatics data, where computer-based bioinformatics databases help scientists create all kinds of data
Such as creating protein sequences, predicting their fields, and producing their three-dimensional structures. Bioinformatics has become a buzz word in science. Many scientists find bioinformatics exciting because it has the ability to dive into a new undiscovered world.
Bioinformatics is a new science and new way of thinking that can lead to many biological discoveries related to this field. Although technology helps bioinformatics, bioinformatics still revolves around biology.
Biological questions lead to all experiments in bioinformatics, and important biological issues can be addressed through bioinformatics. These include: understanding the links between genotypes and phenotypes in human diseases; understanding the relationships between structure and function in proteins; understanding biological networks; Bioinformatics considers that the standard models necessary to answer these exciting biological questions do not exist, so a huge part of the work of bioinformatics is to build tools and techniques as part of the question-asking process.
Bioinformatics is a very popular area, because scientists can use their biological and computer skills to develop standard models of bioinformatics research. Many scientists also find that bioinformatics is a new and exciting field of scientific inquiry with great potential to bring benefits to human health and society.
The future of bioinformatics is integration. It will allow us to integrate a wide range of data sources such as clinical and genomic data, use of disease symptoms to predict genetic mutations, and vice versa. Integration of geographic information system (GIS) such as maps and weather systems with crop health data and pattern data Genetics will allow the prediction of successful results of agricultural experiments. Another area of genetic informatics is comparative genomic studies.
For example, the development of tools that can make comparisons with ten genomics methods will push the rate of discovery in the field of bioinformatics forward. Alongside these lines, models can be created and visualized the complete networks of complex systems in the future predict how the device or cell behaves against the drug.
The technical challenges facing bioinformatics are addressed by the fastest computers and technological improvements in disk storage space and increased bandwidth. However, one of the biggest obstacles facing today's bioinformatics is the presence of a few researchers in the field, search.
The main question of research on the future of bioinformatics is how to compare complex biological observations such as genetic expression patterns and protein networks. For a model the computer can understand.
But this is a very difficult problem, because biology is very complex, and vital informatics in the future faces exciting challenges in how to transform virtual pattern data, such as behaviors, electrical heart image, and crop health into a computer-readable formula.

















0 Comments